rewrite 2.31 (1 repeating) as a simplified fraction.
Answers
\(\frac{20.8}{9}\)
Set \(x\) to 2.31 with 1 repeating.
\(x=2.31...\)
Now multiply the value by 10 so we can have canceling values.
\(10x=23.1...\)
Then we can use elimination.
\(10x=23.1...\)
\(x=2.31...\)
\(9x=20.8\)
\(x=\frac{20.8}{9}\)
Hope this helps.
頑張って!
Answer:
Set to 2.31 with 1 repeating.
Now multiply the value by 10 so we can have canceling values.
Then we can use elimination.
Hope this helps.
Step-by-step explanation:
Related Questions
I just need help with this problem. Show work if possible. Thanks!
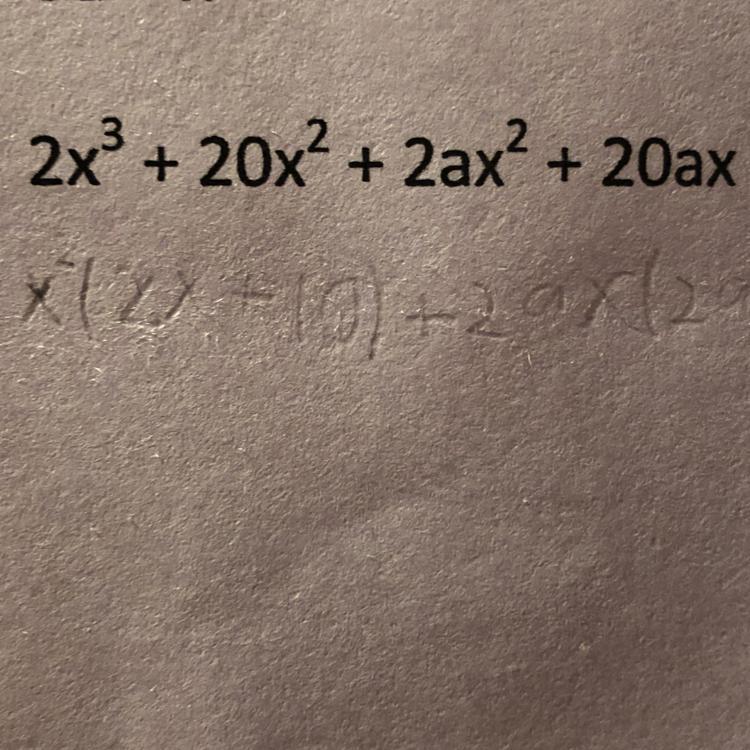
Answers
Answer:
\({:}\longrightarrow\)\(\sf 2x^3+20x^2+2ax^2+20ax \)
\({:}\longrightarrow\)\(\sf 2x^2 (x+10)+2ax (x+10)\)
\({:}\longrightarrow\)\(\sf (x+10)2x^2+2ax\)
\({:}\longrightarrow\)\(\sf (x+10)2x (x+a)\)
\({:}\longrightarrow\)\(\sf 2x (x+a)(x+10)\)
How to simplify it as a fraction?

Answers
0.7 bar can be expressed as 7/9 in fraction.
An element of a whole is a fraction. The number is represented mathematically as a quotient, where the numerator and denominator are divided. Both are integers in a simple fraction. A fraction appears in the numerator or denominator of a complex fraction.
In mathematics, a fraction is referred to as a portion of a whole. For instance, if a pizza is cut into four equal pieces, each one is represented by a quarter. Fractions make calculations quicker and easier by making it easier to distribute and judge numbers.
Part of a whole number and a means of dividing a number into equal parts are represented by fractions. The numerator, also known as the number of equally divided parts, is how it is written.
Learn more about fraction here
https://brainly.com/question/78672
#SPJ9
Blank minus 1/2 equals 3/4
Answers
As the number of degrees of freedom for a t distribution increases, the difference between the t distribution and the standard normal distribution.
Answers
The standard normal distribution becomes smaller.
What is standard deviation?
Your dataset's average level of variability is represented by the standard deviation. It reveals the average deviation of each statistic from the mean. A low standard deviation denotes that values are grouped close to the mean, whereas a large standard deviation shows that values are often far from the mean.Think about the following data: 2, 1, 3, 2, 4. The average and the sum of squares representing the observations' variances from the mean will be 2.4 and 5.2, respectively. This means that (5.2/5) = 1.01 will be the standard deviation.As the number of degrees of freedom for a t distribution increases, the difference between the t distribution and the standard normal distribution
becomes smaller.
Learn more about standard deviation
brainly.com/question/13905583
#SPJ4
Question refer to the attachment !
Don't spam
Don't copy from web !

Answers
The construction of the triangle XYZ with the given specifications is as in the attached image.
Triangle constructionAccording to the question;
We are required to construct ∆XYZ in which case, XY = 6cm, angle measure <ZXY = 30° and m<XYZ = 100°.From the given information, we can evaluate the value of angle measure m<XZY to be 50°.
This is by virtue of the sum of angles in a triangle.
Read more on triangle construction;
https://brainly.com/question/9811089

Help me please. Finals are next week and i’m stuck.

Answers
Answer:
x = 0, x = 7
Step-by-step explanation:
Given equation:
\(\implies \dfrac{x+3}{x-3}+\dfrac{x}{x-5}=\dfrac{x+5}{x-5}\)
Multiply by (x - 5):
\(\implies \dfrac{(x+3)(x-5)}{x-3}+\dfrac{x(x-5)}{x-5}=\dfrac{(x+5)(x-5)}{x-5}\)
Factor out common term (x - 5):
\(\implies \dfrac{(x+3)(x-5)}{x-3}+x=x+5\)
Multiply by (x - 3):
\(\implies \dfrac{(x+3)(x-5)(x-3)}{x-3}+x(x-3)=(x+5)(x-3)\)
Factor out common term (x - 3):
\(\implies (x+3)(x-5)+x(x-3)=(x+5)(x-3)\)
Expand brackets:
\(\implies x^2-5x+3x-15+x^2-3x=x^2-3x+5x-15\)
Combine like terms:
\(\implies 2x^2-5x-15=x^2+2x-15\)
Simplify:
\(\implies x^2-7x=0\)
Factor and solve:
\(\implies x(x-7)=0\)
\(\implies x=0,7\)
Someone in Highschool help?
The graph f(x)=(x+1)2-7is translated 3 units right, resulting in the graph g(x). Write an equation that represents the new function, g(x)
Answers
Step by step solution:
f(x)=(x+1)2-7
f(x)=2x+2-7
f(x)=2x-5
y=2x-5
When it’s translated 3 to the right the y intercept is 3 less if the slope is 1, but since the slope is 2 there the difference is 6, so the y intercept is 6 less than it was before
y=2x-11
. A new diet and exercise program has been advertised as a remarkable way to reduce blood glucose levels in diabetic patients. Fifteen randomly selected diabetic patients are put on the program, and the results after one month were as follows: Before 268 225 252 252 192 307 228 246 298 After 206 186 .223 - 110 293 201 211 Before | 231 185 242 203 198 279 302 After 194 203 250 203 197 234 305 Does the new program reduce blood glucose level in diabetic patients? Use critical vlaue= 1.761 for 0.05 level of significance. Construct the corresponding conifdence interval and interpret it.
Answers
Therefore, we can say with 95% confidence that the mean blood glucose level of diabetic patients after the new program is between 11.29 and 43.59 units lower than before the new program.
The hypothesis tests are used to determine whether the mean of a population is equal to a specified value. In this case, the null hypothesis states that the mean of blood glucose levels of diabetic patients before the new program and after the new program is equal, and the alternative hypothesis states that the mean of blood glucose levels of diabetic patients after the new program is lower than the mean before the new program.
Then the results of the experiment are computed using the below steps. The calculations can be done using statistical software or online calculators.
First, compute the difference between the two means:
$\bar{x}_1 - \bar{x}_2 = 245.87 - 218.43
= 27.44.$
The sample standard deviation is computed using the formula:
$s = \sqrt{\frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 - 2}}
= \sqrt{\frac{(15 - 1)2648.68 + (15 - 1)1329.8}{15 + 15 - 2}}
= 37.1.$
The standard error of the difference is:
$SE = \frac{s}{\sqrt{n_1 + n_2}}
= \frac{37.1}{\sqrt{15 + 15}}
= 9.6.$
The t-statistic is:
$t = \frac{(\bar{x}_1 - \bar{x}_2) - \Delta}{SE}
= \frac{27.44 - 0}{9.6}
= 2.86.$
The p-value is P(t > 2.86) = 0.005.
Since the p-value is less than 0.05, we can reject the null hypothesis at the 0.05 level of significance.
There is evidence that the new program reduces blood glucose levels in diabetic patients.
The confidence interval is calculated as:
$\bar{x}_1 - \bar{x}_2 \pm t_{\alpha / 2}SE,$
where $\alpha$ is the level of significance, t is the t-distribution statistic with $n_1 + n_2 - 2$ degrees of freedom, and SE is the standard error of the difference. For $\alpha = 0.05,$ the critical value is t = 1.761.
The confidence interval is:
$27.44 \pm 1.761 \cdot 9.6,$
or
$(11.29, 43.59).$
To know more about confidence interval visit:
https://brainly.com/question/32546207
#SPJ11
In the diagram, AB is divided into equal parts. The coordinates of point A are (-3, 9), and the coordinates of point Bare (9, 5).
The coordinates of point Care
The coordinates of point E are
The coordinates of point Hare
Answers
The coordinates of points C, E, and H are; (-1.5, 8.5); (1.5, 7.5) and (6, 6)
How to find the coordinates of a divided line?Each section of the line is 1.5 units higher along the x-axis direction and 0.5 units lower than Point A along the y-axis. Thus, for each section you have to add 1.5 to x-coordinates and subtract 0.5 from y-coordinate values.
Thus;
Point A has a coordinate of (-3, 9).
Point C is one section away from point A and as such the coordinates of section C is;
C = ((-3 + 1.5), (9 - 0.5))
C = (-1.5, 8.5)
Applying the same for points E and H are;
E(1.5, 7.5) and H(6, 6)
Read more about Line Coordinates at: https://brainly.com/question/7243416
#SPJ1
FILL THE BLANK.
For a 2x2 contingency table, testing for independence with the chi-square test is the same as conducting a ____________ test comparing two proportions.
Answers
The chi-square test for independence in a 2x2 contingency table is equivalent to comparing two proportions to determine if they are significantly different.
For a 2x2 contingency table, testing for independence with the chi-square test is the same as conducting a test comparing two proportions, specifically the two proportions of one variable (column) against the proportions of another variable (row).
1. Start with a 2x2 contingency table, which is a table that displays the counts or frequencies of two categorical variables. The table has two rows and two columns.
2. Calculate the marginal totals, which are the row and column totals. These represent the totals for each category of the variables.
3. Compute the expected frequencies under the assumption of independence. To do this, multiply the row total for each cell by the column total for the same cell, and divide by the total sample size.
4. Use the chi-square test statistic formula to calculate the chi-square value. This formula involves subtracting the expected frequency from the observed frequency for each cell, squaring the difference, dividing by the expected frequency, and summing up these values for all cells.
5. Determine the degrees of freedom for the chi-square test. In this case, it is (number of rows - 1) multiplied by (number of columns - 1), which is (2-1) x (2-1) = 1.
6. Compare the calculated chi-square value to the critical chi-square value from the chi-square distribution table at the desired significance level (e.g., 0.05).
7. If the calculated chi-square value is greater than the critical chi-square value, then the proportions of the two variables are significantly different, indicating dependence. If the calculated chi-square value is not greater, then the proportions are not significantly different, suggesting independence.
In summary, testing for independence with the chi-square test for a 2x2 contingency table is equivalent to conducting a test comparing two proportions, where the proportions represent the distribution of one variable against another.
Learn more About chi-square test from the given link
https://brainly.com/question/4543358
#SPJ11
the p-value for a hypothesis test turns out to be 0.07702. at a 1% level of significance, what is the proper decision?
Answers
7.702 is the proper decision.
What exactly is a p-value?
The p-value (probability value) indicates how likely the data are to occur under the null hypothesis. To do this, the probability of the test statistic is computed. H. Numbers calculated by statistical tests using your data.The p-value indicates how often you would expect the test statistic to be extreme, or more extreme than the statistic computed by the statistical test, if the null hypothesis for the test were true. The p-value decreases as the test statistic computed from the data moves away from the range of the test statistic predicted by the null hypothesis.To know more about p-value visithttps://brainly.com/question/16754784#SPJ4you pick four cards from a deck with replacing the card each time before picking the next card. what is the probability that all four cards are kings? round to six decimal places, if necessary.
Answers
1/28561 is the probability that all four cards are kings
What is deck?Hearts, clubs, spades, and diamonds make up the four suites of a normal deck of cards. thirteen cards total—aces, 2, 3, 4, 5, 6, 7, 8, 9, 10, jack, queen, and king—make up each suite. Thus, there are 52 cards in all in the deck.
The four French suits—clubs, diamonds, hearts, and spades—each have 13 ranks. King, Queen, and Jack are the three court cards (face cards) in each suit, and their pictures are reversed (double-headed). The ten numerical cards, or pip cards, in each suit range in value from one to 10.
In a pack of cards, there are 52 cards and 4 Kings.
Probability of picking a King is: 4/52 = 1/13 .
Since a card is being replaced before picking up the next card, the probability of picking a King is always 1/13 .
Picking a subsequent King is independent of picking a King previously and thus we multiply the individual probabilities to arrive at the combined probability.
Thus, the required probability is:
= 1/13 × 1/13 × 1/13 × 1/13
= 1/28561
To know more about probability refer to:
https://brainly.com/question/13604758
#SPJ4
B is the midpoint of AC. AB = 2x+12 and BC = 5x + 10. Find AC
Answers
Answer:
x=6
Step-by-step explanation:
/AB/=2x+12
/BC/=5x+10
3x+2=5x-10 subtract 2 from both sides
3x=5x-12 subtract 5x from both sides
-2x=-12 divide both sides by -2x
x =6
What's the slope? (-19, 12), (-9,1)
Answers
Why?
To find skip you do the difference of Y/ the difference of x. So...
12+9/ -19-1 = 21/-20
Hope this helps :D
Answer:
Slope: -11/10
Step-by-step explanation:
always do y2 - y1/x2 - x1
12 - 1 / -19 + 9 = -11/10
Prove that the following equation has exactly one solution in (−1,0):
x^5 + 5x + 1 = 0.
Answers
Prove that the equation \(x^5 + 5x + 1 = 0\) has exactly one solution in the interval (-1, 0).
To prove that the equation has exactly one solution in the given interval, we can use the Intermediate Value Theorem. According to this theorem, if a continuous function takes on different signs at two points in an interval, then it must have at least one root (solution) in that interval.
In this case, consider the function f(x) = \(x^5 + 5x + 1\). We can observe that f(-1) = -5 and f(0) = 1. Since f(-1) is negative and f(0) is positive, the function changes sign within the interval (-1, 0). Therefore, by the Intermediate Value Theorem, there must exist at least one root of the equation \(x^5 + 5x + 1 = 0\) in the interval (-1, 0).
To show that there is exactly one solution, we need to establish that the function does not change sign again within the interval. This can be done by analyzing the behavior of the function and its derivative. By studying the derivative, we can confirm that the function is increasing and crosses the x-axis only once in the given interval, ensuring that there is a single solution.
Therefore, we have proven that the equation \(x^5 + 5x + 1 = 0\) has exactly one solution in the interval (-1, 0).
Learn more about Theorem here:
https://brainly.com/question/30066983
#SPJ11
question: a researcher wishes to estimate, with 99% confidence, the population proportion of families who eat fast food at least once per week. her estimate must be accurate within 4% of the population proportion. (a) no preliminary estimate is available. find the minimum sample size needed. (b) find the minimum sample size needed, using a prior study that found that
Answers
The result from part (b) is smaller than the result from part (a), indicating that having an estimate of the population proportion reduces the minimum sample size needed.
(a) To find the minimum sample size needed when no preliminary estimate is available, we can use the formula:
\(n = (z^2 * p * (1 - p)) / E^2\)
where:
z = the z-score corresponding to the confidence level (99% confidence level has a z-score of 2.576)
p = the estimated population proportion (we don't have an estimate, so we'll use 0.5 for maximum variability)
E = the maximum error of the estimate (4% = 0.04)
Plugging in the values, we get:
\(n = (2.576^2 * 0.5 * (1 - 0.5)) / 0.04^2\\n = 659.36\)
Round up to the nearest whole number, we get a minimum sample size of 660.
(b) Using previous research where 20% of the respondents claimed to eat fast food four to six times per week, we can apply the following calculation to get the minimal sample size required:
\(n = (z^2 * p * (1 - p)) / E^2\)
where:
z = the z-score corresponding to the confidence level (99% confidence level has a z-score of 2.576)
p = the estimated population proportion (we have an estimate of 0.2)
E = the maximum error of the estimate (4% = 0.04)
Plugging in the values, we get:
\(n = (2.576^2 * 0.2 * (1 - 0.2)) / 0.04^2\\n = 320.34\)
Round up to the nearest whole number, we get a minimum sample size of 32.
(c) The result from part (b) is smaller than the result from part (a), indicating that having an estimate of the population proportion reduces the minimum sample size needed.
Population proportion refers to the proportion of individuals in a given population who possess a particular characteristic of interest. It is a statistical concept used to estimate the frequency of a specific attribute or behavior in a larger population. For instance, if we want to know the proportion of people in a city who own a car, we can randomly select a sample of people from the city and determine the percentage of people in the sample who own a car. This percentage can then be used to estimate the population proportion.
Population proportion is an important concept in statistical inference, where researchers use a sample to make inferences about the entire population. To ensure accurate estimation, the sample must be representative of the population being studied. Moreover, statistical techniques such as confidence intervals and hypothesis testing can be used to determine the degree of confidence in the estimated population proportion.
To learn more about Population proportion visit here:
brainly.com/question/16879541
#SPJ4
Complete Question:-
A researcher wishes to estimate, with 99% confidence, the population proportion of adults who eat fast food four to six times per week. Her estimate must be accurate within 4% of the population proportion
(a) No preliminary estimate is available. Find the minimum sample size needed.
(b) Find the minimum sample size needed, using a prior study that found that 20% of the respondents said they eat fast food four to six times per week.
(c) Compare the results from parts (a) and (b)
The measurement of the edge of a cube is found to be 17 inches, with a possible error of 0.02 inch. Use differentials dy = f'(x)dx to estimate the propagated error in computing (a) the volume of the cube (v = ?) and (b) the surface area (S = 6x®) of the cube. Give your answers to two decimal places. a) 13.87, 3.67 b) 20.81, 4.08 C) 17.34, 4.08 d) 15.61, 3.67 e) 13.87, 3.26
Answers
The error in the volume is 17.34, and in the surfacearea is 4.08.
The correct option is C.
How to find the surface area?To estimate the propagated error in computing the volume and surface area of a cube based on the given measurement and possible error, we can use differentials. Differentials provide an approximation of the change in a function due to a small change in its independent variable.
Let's denote:
x as the edge length of the cube (17 inches in this case).dx as the possible error in the measurement (0.02 inch in this case).V as the volume of the cube.A as the surface area of the cube.(a) Propagated error in computing the volume:The volume of a cube is given by V = x³. Taking the derivative of the volume function with respect to x, we have f'(x) = 3x²Using differentials, we can estimate the propagated error in computing the volume as follows:
dy = f'(x) * dx
deltaV = f'(x) * dx
deltaV = 3x² * dx
Substituting the values:
deltaV = 3 * (17²) * 0.02
deltaV ≈ 17.34 cubic inches
Therefore, the propagated error in computing the volume of the cube is approximately 173.04 cubic inches.
(b) Propagated error in computing the surface area:
The surface area of a cube is given by A = 6x^2. Taking the derivative of the surface area function with respect to x, we have f'(x) = 12x.
Using differentials, we can estimate the propagated error in computing the surface area as follows:
dy = f'(x) * dx
deltaA = f'(x) * dx
deltaA = 12x * dx
Substituting the values:
deltaA = 12 * 17 * 0.02
deltaA ≈ 4.08 square inches
The propagated error in computing the surface area of the cube is approximately 4.08 square inches.
Learn more about surface area:
https://brainly.com/question/16519513
#SPJ4
Use the value of the linear correlation coefficient r to find the coefficient of determination and the percentage of the total variation that can be explained by the linear relationship between the two variables. r = 0.6
What is the value of the coefficient of determination?
What is the percentage of the total variation that can be explained by the linear relationship between the two variables?
Answers
Answer:
The value of the coefficient of determination is 0.36, and 36% of the total variation in the dependent variable can be explained by the linear relationship with the independent variable.
Step-by-step explanation:
The coefficient of determination, denoted as r^2, is obtained by squaring the linear correlation coefficient r.
In this case, since r = 0.6, we can calculate the coefficient of determination as follows:
r^2 = (0.6)^2 = 0.36
The coefficient of determination, r^2, represents the proportion of the total variation in the dependent variable (Y) that can be explained by the linear relationship with the independent variable (X).
To express this as a percentage, we multiply r^2 by 100:
Percentage of total variation explained = r^2 * 100 = 0.36 * 100 = 36%
To learn more about Coefficient
brainly.com/question/25844871
#SPJ11
Which of the following data collection methods involves studying individuals without making an attempt to influence the results? Choose the best answer.a. observational studyb. causationc. experimentd. sample survey
Answers
Solution
For this case the only collection method thats satisfy very well the definition given is:
d. sample survey
Your uncle has $1,375,000 and wants to retire. He expects to live for another 25 years and to earn 5.5% on his invested funds. How much could he withdraw at the end of each of the next 25 years and end up with zero in the account?
Answers
SORRY PLEASE DELETE THIS ANSWER IT ISN'T GOOD AND IS INCOMPLETE I ACCIDENTALLY WROTE IT
please help me, someone!

Answers
Answer:
76.275
Step-by-step explanation:
First - the entire circles area is 78.54. \(\pi r^{2}\) with r being 5
6 triangles of that size could fit in that circle.
A=3\(\sqrt{3}\)/(2) * a2
The area of that would equal 64.95
78.54-64.95 = 13.59
then divide that number by 6
which is 2.265.
Take that number from the original 78.54
78.54-2.265 = 76.275
a car manufacturer is looking to compare the sales of their sedan model last year to the sales of the same model 15 years ago at various dealerships. the manufacturer is weighing two different proposals to conduct the study. under the first proposal, the manufacturer randomly samples 10 different dealerships for their sales numbers last year and randomly selects another 10 dealerships for their sales numbers 15 years ago. in the second proposal, the manufacturer randomly samples 10 dealerships for both sets of sales numbers. are the samples in these proposals dependent or independent?
Answers
The samples in the first proposal are independent, while the samples in the second proposal are dependent.
In the first proposal, where the manufacturer randomly samples 10 different dealerships for each set of sales numbers (last year and 15 years ago), the samples are independent. This is because the selection of dealerships for one set of sales numbers does not affect or influence the selection of dealerships for the other set of sales numbers. Each dealership is chosen randomly and independently for each set.
On the other hand, in the second proposal, where the manufacturer randomly samples 10 dealerships for both sets of sales numbers, the samples are dependent. This is because the selection of dealerships for one set of sales numbers is directly tied to the selection of dealerships for the other set of sales numbers. The same 10 dealerships are chosen for both sets, so the samples are not independent.
The choice between independent and dependent samples can have implications for statistical analysis. Independent samples allow for direct comparisons between the two sets of sales numbers, while dependent samples may introduce potential bias or confounding factors due to the shared dealership selection.
Learn more about statistical analysis here:
https://brainly.com/question/14724376
#SPJ11
A ______ equation is an equation in which each term is either a constant or the product of a constant and a single variable.
Answers
Answer:
linear
Step-by-step explanation:
hey there,
< Linear equations are constant. They are not like parabolas so they are not curved but instead are straight, which allows them to be constant. >
Hope this helped! Ask me any more questions if you still don't understand!
Answer: The answer is a Linear Function
Step-by-step explanation:
Chebyshev's theorem provides the proportion of observations that lie within k standard deviations of the mean. The value k must be ______.
Answers
The value of k in Chebyshev's theorem can be any positive real number.
Chebyshev's theorem, also known as Chebyshev's inequality, is a statistical theorem that provides an upper bound on the proportion of observations that lie within a certain number of standard deviations from the mean in any distribution.
The theorem states that for any distribution (regardless of its shape), at least \((1 - 1/k^2)\) proportion of the data falls within k standard deviations from the mean, where k is any positive number greater than 1.
Mathematically, Chebyshev's theorem can be expressed as:
P(|X - μ| < kσ) ≥ \(1 - 1/k^2\)
Where:
P(|X - μ| < kσ) represents the probability that a randomly selected observation from the distribution falls within k standard deviations from the mean.
μ represents the mean of the distribution.
σ represents the standard deviation of the distribution.
k is the number of standard deviations from the mean.
The value of k in Chebyshev's theorem can be any positive real number.
Learn more about Chebyshev's theorem at:
brainly.com/question/231802
#SPJ4
A recipe for fruit salad includes ¼ cups of grapes for 16 servings.
How many cups of grapes are needed for 20 servings of this fruit salad?

Answers
The number of cups of grapes that are needed for 20 servings of fruit salad is 5/16 cups of grapes.
Given the following data:
Quantity of grapes = 1/4 cups
Number of servings = 16 servings.
To determine how many cups of grapes are needed for 20 servings of fruit salad, we would use direct proportion:
By using direct proportion:
1/4 cups of grapes = 16 servings.
X cups of grapes = 20 servings.
Cross - Multiply, we have
16X = 1/4 x 20
16X = 5
X = 5/16 cups of grapes
Learn more about Cups of fruits at:
https://brainly.com/question/11485857
#SPJ1
Use this diagram and information given to find m_DFC.
B
C с
А
F
KE
D
Given: m_AFB = m_EFD = 35°
Points B,F,D and points E, F, C are collinear.
The measure of ZDFC is 9

Answers
Find the value of X.

Answers
Answer:
x=60
Step-by-step explanation:
Answer:
X - 60 is the answer
Hope thus is helpful
!!!!!!!!!!!!!!!!!!!!!!!

Answers
To understand the effect of the function g(x) = |3x| + 1, we need to compare it with the original function f(x) = 3x.The absolute value function |3x| takes any negative input value and makes it positive, so it reflects the left half of the graph of f(x) across the x-axis. This means that the graph of g(x) will have the same shape as f(x) for positive x-values, but will be reflected across the x-axis for negative x-values.Additionally, the function g(x) adds 1 to the output of |3x|, so the entire graph of g(x) is shifted up by 1 unit.Therefore, the correct answer is C. The graph of g(x) is compressed horizontally (due to the absolute value function) and shifted up 1 unit.
Question 9 answer please

Answers
9) The measure of each labelled angles are x=103°, x-26°=77°
10) The measure of each labelled angles are x/2=12°, 7x=168°
11) The measure of each labelled angles are (3x-5)°=85° and x+55°=85°
12) The measure of each labelled angles are x+10°=85°,x+20°=95°,
y-40°=70°, y=110°
What is meant by an angle?In Euclidean geometry, an angle is a figure made up of two rays that have a shared vertex, also known as a common terminus, and are referred to as the angle's sides. The angles of two rays are situated in the plane containing the rays. An angle is also created when two planes intersect at an angle. These are referred to as dihedral angles.
9) For a parallelogram opposite angles are equal and the sum of total interior angles is 360°
Here, x°+x°+(x-26°)+(x-26°)
=4x-52=360
4x=412
x=103°
x-26°=77°
10) Here,
7x+(x/2)+90+90=360
15x/2=180
x=24°
Indicated angles are x/2=12°
And 7x=168°
11) Here,
3x-5=x+55
2x=60°
x=30°
Indicated angles,
(3x-5)°=85°
And x+55°=85°
12) Here,
x+20°+x+10°=180°
2x=150°
x=75°
Here,
y-40°=180-y°
2y=220°
y=110°
Indicated angles,
x+10°=85°
x+20°=95°
y-40°=70°
y=110°
To know more about angle, visit:
https://brainly.com/question/28451077
#SPJ1
Given circle O shown, find the following measurements. Round your answers to the nearest whole number. Use 3.14 for π .

Answers
In the given diagram of circle O, we need to find various measurements. Let's consider the following measurements:
Diameter (d): The diameter of a circle is the distance across it, passing through the center. To find the diameter, we can measure the distance between any two points on the circle that pass through the center. Let's say we measure it as 12 units.
Radius (r): The radius of a circle is the distance from the center to any point on the circumference. It is half the length of the diameter. In this case, the radius would be 6 units (12 divided by 2).
Circumference (C): The circumference of a circle is the distance around it. It can be found using the formula C = 2πr, where π is approximately 3.14 and r is the radius. Using the radius of 6 units, we can calculate the circumference as C = 2 * 3.14 * 6 = 37.68 units. Rounding to the nearest whole number, the circumference is approximately 38 units.
Area (A): The area of a circle is the measure of the surface enclosed by it. It can be calculated using the formula A = πr^2. Substituting the radius of 6 units, we can find the area as A = 3.14 * 6^2 = 113.04 square units. Rounding to the nearest whole number, the area is approximately 113 square units.
In summary, for circle O, the diameter is 12 units, the radius is 6 units, the circumference is approximately 38 units, and the area is approximately 113 square units.
For more such questions on various measurements
https://brainly.com/question/27233632
#SPJ8