Peetyn Schmidt - Find the par, whole of percent homework
file Edit View Insert Format Slide Arrange Tools Add-ons Help Last edit was 3 days
ago
FA
Background
Layout
Theme
Transition
NE
FARINE PARTNER PRINE
What x2
18h
2
. a text
12 what
What
What
MANSON
Wes1
18h what
11
ia
what
we
IL
18
IR
16
18
1
12
1 What
I had
18
IA
Answers
Related Questions
How do I do all of these questions for this one? Please help :(

Answers
Can someone help me solve this?

Answers
The function is an exponential growth since it is increasing with time and k is positive
What is exponential growth?
Given that at t =6, P = 167075
Then;
167075 =110.8e^6k
167075/110.8 = e^6k
1507.9 = e^6k
ln(1507.9) = 6k
k = ln(1507.9)/6
k = 1.2
Thus in the year 2020;
P = 110.8e^20(1.2)
P = 2.9 * 10^12
In the year 2025;
P = 110.8e^25(1.2)
P = 1.18 * 10^15
To reach 290,000
290,000 = 110.8e^1.2t
290000/110.8 = e^1.2t
2617.3 = e^1.2t
t = ln(2617.3 )/1.2
t = 7 years
Learn more about exponential:https://brainly.com/question/28596571
#SPJ1
WILL MARK AS BRAINLEIST!!!!!!
Suppose f(x)=x² where p > 1 and
[a, b] = [0, 1]. According to the Mean Value Theorem there is at least one number c such that
f(b) - f(a) = f'(c)(b-a).
Actually, in this particular case the number c is unique but it depends on p. In fact,
C=________
Your answer will be in terms of p.
Answers
Therefore, the unique value of c for this case is 1/2, which does not depend on p.
What is mean value theorem?The Mean Value Theorem is a fundamental result in calculus that relates
f(b) - f(a) = f'(c) (b - a).
by the question.
We have, f(x) = x², where p > 1 and [a, b] = [0, 1].
Then, f(a) = f(0) = 0 and f(b) = f(1) = 1.
Also, f'(x) = 2x.
Now, by the Mean Value Theorem, there exists at least one number c in (a, b) such that:
f(b) - f(a) = f'(c)(b-a)
Substituting the values, we get:
1 - 0 = f'(c)(1-0)
1 = 2c
c = 1/2
To learn more about height:
https://brainly.com/question/30365299
#SPJ1
X-7/20=5/16 solve for x
Answers
x = 53/80 = 0.6625
if isn't right I have another equation
Answer:
13.25
Step-by-step explanation:
\(x - 7 \div 20 = 5 \div 16\)
by cross multiplying
16(x-7)=5(20)
16x-112=100
16x=100+112
16x=212
x=212 /16
×=13.25
if the question is this

Rearrange the equation so m is the independent variable
-2m-5n=7m-3n
Answers
The equation rearranged so that m is the independent variable is n = (9/11)m
To rearrange the equation -2m - 5n = 7m - 3n so that m is the independent variable, we need to isolate the term that contains m on one side of the equation. We can do this by adding 2m to both sides and then subtracting 3n from both sides. This gives us:
-2m - 5n + 2m = 7m - 3n + 2m - 3n
-5n = 9m - 6n
Now, we can further isolate the term containing m by subtracting 6n from both sides and then dividing both sides by 9:
-5n - 6n = 9m - 6n - 6n
-11n = 9m - 12n
-11n + 12n = 9m
n = (9/11)m
Therefore, the equation rearranged so that m is the independent variable is:
n = (9/11)m
This equation expresses n in terms of m, where m is the independent variable, and n depends on m. We can use this equation to determine the value of n for a given value of m.
To learn more about equation click on,
https://brainly.com/question/16453449
#SPJ1
a bakery can make 8 cheesecakes for every 8 blocks of cream cheese which table represents the relationship between the number of cheesecakes the bakery makes and the number of blocks of cream cheese the bakery uses

Answers
Answer:
d
Step-by-step explanation:
The maintenance manager at a trucking company wants to build a regression model to forecast time until the first engine overhaul based on four explanatory variables: (1) annual miles driven, (2) average load weight, (3) average driving speed, and (4) oil change interval. Based on driver logs and onboard computers, data have been obtained for a sample of 25 trucks.
a.Estimate the time until the first engine overhaul as a function of all four explanatory variables.
b-1.At the 10% significance level, are the explanatory variables jointly significant? First, specify the competing hypotheses.
b-2.What is the p-value for the test on joint significance?
b-3.What is the conclusion to the test on joint significance?
c-1.Are the explanatory variables individually significant at the 10% significance level? First, specify the competing hypotheses.
c-2.What are the p-values and conclusions for the tests on individual significance for each explanatory variable?
Answers
The maintenance manager of a trucking firm wishes to create a regression model based on four explanatory variables: (1) annual miles travelled, (2) average load weight, (3) average driving speed, and (4) oil change interval to anticipate when the first engine overhaul will occur. Data have been acquired for a sample of 25 vehicles based on driver logs and onboard computers, Based on given information, description of asked questions are as follow-
a. The maintenance manager can estimate the time until the first engine overhaul by building a regression model using the four explanatory variables: annual miles driven, average load weight, average driving speed, and oil change interval. In regression analysis, the manager can use the sample data of 25 trucks to estimate the relationship between the explanatory variables and the time until the first engine overhaul. By fitting the data to a regression model, the manager can obtain the coefficients for each explanatory variable, indicating their impact on the time until the first engine overhaul.
This model can then be used to forecast the time until the first engine overhaul for future trucks based on their values for the explanatory variables.b-1. The competing hypotheses for testing the joint significance of the explanatory variables are as follows:
- Null hypothesis (H0): The coefficients of all four explanatory variables are equal to zero (no significant relationship).
- Alternative hypothesis (Ha): At least one of the coefficients of the explanatory variables is not equal to zero (significant relationship exists).
b-2. To determine the p-value for the test on joint significance, the manager needs to perform a statistical test, such as the F-test, to assess the overall significance of the explanatory variables. The p-value represents the probability of obtaining the observed test statistic or a more extreme value, assuming the null hypothesis is true. The specific p-value can be obtained from the F-distribution.
b-3. The conclusion to the test on joint significance depends on comparing the obtained p-value to the predetermined significance level (in this case, 10%). If the p-value is less than 0.10, the manager can reject the null hypothesis and conclude that the explanatory variables have a joint significant effect on the time until the first engine overhaul. Conversely, if the p-value is greater than or equal to 0.10, there is insufficient evidence to reject the null hypothesis, indicating that the explanatory variables do not have a joint significant effect.c-1. To assess the individual significance of the explanatory variables at the 10% significance level, the following competing hypotheses can be specified for each variable:
- Null hypothesis (H0): The coefficient of the individual explanatory variable is equal to zero (no significant relationship).
- Alternative hypothesis (Ha): The coefficient of the individual explanatory variable is not equal to zero (significant relationship exists).
c-2. To determine the p-values and conclusions for the tests on individual significance, the manager needs to perform separate statistical tests for each explanatory variable, such as t-tests. The p-value represents the probability of obtaining the observed test statistic or a more extreme value, assuming the null hypothesis is true.
If the p-value is less than 0.10, the manager can reject the null hypothesis and conclude that the individual explanatory variable is significant. On the other hand, if the p-value is greater than or equal to 0.10, there is insufficient evidence to reject the null hypothesis, indicating that the individual explanatory variable is not significant at the 10% significance level.
Learn more about Null hypothesis
https://brainly.com/question/30821298
#SPJ11
Graph the inverse of the provided graph on the accompanying set of axes. You must
plot at least 5 points.

Answers
Answer:
*See attached image for the 5 points on the graph*
Step-by-step explanation:
Step 1: Find 5 points to calculate inverse
We can use the vertex(-1,-4), 2 y-intercepts(0,-3) and (0,-5) and 2 more points (3,-2) and (3,-6)
Step 2: Find the inverse
You find the inverse when you swap the 'x' and 'y' so it would be
Vertex: (-4,-1)
y-intercept 1:(-3,0)
y-intercept 2:(-5,0)
Point 1: (-2,3)
Point 2: (-6,3)
Step 3: Graph
Graph the points on a graph and connect the points

The inverse of a graph is done by reflecting the graph across the line \(y = x\).
See attachment for the inverse graph.
From the given graph, we have the following 5 points.
\((x_1,y_1) = (8,-1)\)
\((x_2,y_2) = (3,-2)\)
\((x_3,y_3) = (-1,-4)\)
\((x_4,y_4) = (3,-6)\)
\((x_5,y_5) = (8,-7)\)
Reflect the above points across \(y = x\), to get the inverse function
\((x_1,y_1) = (-1,8)\)
\((x_2,y_2) = (-2,3)\)
\((x_3,y_3) = (-4,-1)\)
\((x_4,y_4) = (-6,3)\)
\((x_5,y_5) = (-7,8)\)
The inverse graph must pass through the above points
See attachment for the inverse graph
Read more about inverse graphs at:
https://brainly.com/question/11033643

Helppppp!!!!!! Quick :(((

Answers
A pot contains 3/4 gallon of soup.A serving is 1/16 gallon.How many servings does the pot contain?
Answers
by taking the quotient between the volume in the pot and the volume of each serving, we conclude that there are 12 servings.
How many servings does the pot contain?
The number of servings is given by the quotient between the volume in the pot and the volume of each serving, so we have:
Volume in the pot = 3/4 gallon.Volume of each serving = 1/16 gallon.N = (3/4)*/(1/16) = 12
So there are 12 servings in the pot.
If you want to learn more about quotients:
https://brainly.com/question/8952483
#SPJ1
You roll a six-sided die. What is the probability that it is a 5 or an even number? Write your answer as a decimal rounded to the nearest thousandth. The probability is about
Answers
Answer:
4/6 chance
Step-by-step explanation:
there is a 4/6 probability this will happen
A group of 200 adults were asked whether they exercise and what they are vegetarian
Answers
Step-by-step explanation:
(a) What percentage of the adults exercise?
₹
(b) What percentage of the adults are vegetarian?
€
(c) What percentage of the adults who are vegetarian exercise? [ (d) Is there evidence that adults who are vegetarian tend to be exercisers more often than average?
Yes, because the percentage found in part (c) is much greater than the percentage found in part (a).
Yes, because the percentage found in part (c) is much greater than the percentage found in part ((b).
No, because the percentage found in part (c) is about the same as the percentage found in part ((a).
No, because the percentage found in part (c) is about the same as the percentage found in part ((b).
On Saturday morning, Owen earned $27. By the end of the afternoon he had earned a total of $62. Enter an equation, using x as your variable, to determine whether Owen earned $35 or $33 on Saturday afternoon.
Answers
Answer:just hart me n I will help
Step-by-step explanation:
=
−
2
x
+
5
y
=
-
2
x
+
5
Use the slope-intercept form to find the slope and y-intercept.
Tap for more steps...
Slope:
−
2
-
2
y-intercept:
(
0
,
5
)
(
0
,
5
)
Any line can be graphed using two points. Select two
x
x
values, and plug them into the equation to find the corresponding
y
y
values.
Tap for more steps...
x
y
0
5
5
2
0
Find The Area of the parallelogram...

Answers
Answer:
162 ft^2
Step-by-step explanation:
the formula for finding the area of a triangle is \(\frac{b*h}{2}\)
the base is 27 and the height is 12
\(\frac{27*12}{2}=\frac{324}{2} = 162\)
(27 X 12)/2 = 324/2 = 162ft^2
What is the y-coordinate of point D after a translation of (x, y) → (x + 6, y – 4)?

Answers
Translating the triangle DEF involves moving the triangle along the coordinate plane
The y-coordinate of point D after the translation (x, y) → (x + 6, y – 4) is 1
How to determine the y-coordinate of D'?From the figure the coordinate of D is:
D = (-2.5,5)
The rule of translation is given as:
(x, y) → (x + 6, y – 4)
So, we have:
(x, y) → (-2.5 + 6, 5 – 4)
Evaluate the sum and the difference
(x, y) → (3.5, 1)
Remove the x-coordinate
y → 1
Hence, the y-coordinate of point D after the translation is 1
Read more about translation at:
https://brainly.com/question/11468584
Consider the multiple regression model with two regressors X1 and X2, where both variables are determinants of the dependent variable. You first regress Y on X1 only and find no relationship. However when regressing Y on X1 and X2, the slope coefficient changes by a large amount. This suggests that your first regression suffers from a. heteroskedasticity b. perfect multicollinearity c. omitted variable bias d. dummy variable trap 8. Imperfect multicollinearity a. implies that it will be difficult to estimate precisely one or more of the partial effects using the data at hand b. violates one of the four Least Squares assumptions in the multiple regression model c. means that you cannot estimate the effect of at least one of the Xs on Y d. suggests that a standard spreadsheet program does not have enough power to estimate the multiple regression model
Answers
Some part of the regression can be estimated precisely, but it is difficult to predict the effect of individual regressors when there is multicollinearity in the data.Multiple regression models require that variables be independent of one another, otherwise, multicollinearity will occur.
Consider the multiple regression model with two regressors X1 and X2, where both variables are determinants of the dependent variable. You first regress Y on X1 only and find no relationship. However when regressing Y on X1 and X2, the slope coefficient changes by a large amount.
This suggests that your first regression suffers from omitted variable bias. Imperfect multicollinearity implies that it will be difficult to estimate precisely one or more of the partial effects using the data at hand. Imperfect multicollinearity means that there is a strong correlation between the regressors, but they are not perfectly correlated.
As a result, some part of the regression can be estimated precisely, but it is difficult to predict the effect of individual regressors when there is multicollinearity in the data.Multiple regression models require that variables be independent of one another, otherwise, multicollinearity will occur.
When there is multicollinearity in the data, it means that two or more of the variables are highly correlated with one another. In other words, the data may contain redundant information, which can make it difficult to estimate the regression coefficients or partial effects.The dummy variable trap refers to a situation in which one of the variables is a perfect linear combination of the other variables.
This results in the model being unsolvable, and the coefficients cannot be estimated. Heteroskedasticity is the term used to describe when the variance of the residuals is not constant across all values of the independent variables. This means that the predictions of the model may be biased, and the standard errors of the coefficients may be incorrect.
For more such questions on multicollinearity, click on:
https://brainly.com/question/15856348
#SPJ8
3 Tyler traveled at an average speed of 50 miles per hour for 3.5 hours and then traveled at an average speed of 65 miles per hour for 2.5 hours. What was the total distance in miles that Tyler traveled during this time? KS
Answers
ANSWER:
A. 337.5 miles
STEP-BY-STEP EXPLANATION:
What we must do is calculate the distance in each section, when the speed and time vary, the sum of both section is the total distance:
Section 1:
\(50\frac{\text{ miles}}{\text{ hours}}\cdot3.5\text{ hours}=175\text{ miles}\)Section 2:
\(65\frac{\text{ miles}}{\text{ hours}}\cdot2.5\text{hours}=162.5\text{ miles}\)The total distance is:
\(d=175+162.5=337.5\text{ miles}\)If the odds against debroah's winning first prize are 3 to 5, what is the probability that she will win 1st prize?
Answers
Answer:
See below
Step-by-step explanation:
Odds AGAINST are 3 to5 then odds FOR are 2 to 5
2/5 = .4 = 40% chance of winning
simplify (3x+2)(3x-2)
Answers
Answer:
9 (*2) − 4
Step-by-step explanation:
the *2 is the square unit
How much money will be in an account with an initial investment of $13, 675 at 4.3% interest over 5
years if the interest is compounded annually?
Answers
Sanjay stacks three boxes in a pile. The heights of the boxes are 25cm 36cm and 47cm. They are all measured correct to the nearest centimetre. What is the greatest possible height of the stack of the three boxes?
Answers
A photo of a beetle in science is increased to 66% as large as the actual size. If the beetle is 15 millimeters, what is the size of the beetle in the photo?

Answers
The size of the beetle in the photo can be calculated by multiplying the actual size of the beetle (15 mm) by the percentage increase (66%). The calculation is as follows: 15 mm x 66% = 9.9 mm. Therefore, the size of the beetle in the photo is 9.9 mm.
To understand this calculation better, it is helpful to break it down into its individual components. The actual size of the beetle is 15 mm, which is the size of the beetle before it is increased. The percentage increase is 66%, which means that the size of the beetle will be increased by 66% of its original size. The calculation then multiplies the actual size of the beetle (15 mm) by the percentage increase (66%) to determine the size of the beetle in the photo (9.9 mm).This calculation can be used to determine the size of any object in a photo that has been increased to a certain percentage of its original size. All that is needed is the actual size of the object and the percentage increase. The calculation can then be used to determine the size of the object in the photo.
Learn more about percentage here:
https://brainly.com/question/26352729
#SPJ1
Which one of the following would be most helpful in strengthening the content validity of a test?
A. Administering a new test and an established test to the same group of students.
B. Calculating the correlation coefficient.
C. Calculating the reliability index.
D. Asking subject matter experts to rate each item in a test.
Answers
Asking subject matter experts to rate each item in a test would be most helpful in strengthening the content validity of a test
Asking subject matter experts to rate each item in a test would be most helpful in strengthening the content validity of a test. Content validity refers to the extent to which a test accurately measures the specific content or domain it is intended to assess. By involving subject matter experts, who are knowledgeable and experienced in the domain being tested, in the evaluation of each test item, we can gather expert opinions on the relevance, representativeness, and alignment of the items with the intended content. Their input can help ensure that the items are appropriate and adequately cover the content area being assessed, thus enhancing the content validity of the test.
Know more about subject matter experts here:
https://brainly.com/question/31154372
#SPJ11
juan owns 7 pairs of pants, 5 shirts, 6 ties, and 8 jackets. how many different outfits can he wear to school if he must wear one of each item?
Answers
Answer: I believe he could wear 768 outfits
Step-by-step explanation: I had a similar question consisting of the same numbers.
nasa is conducting an experiment to find out the fraction of people who black out at g forces greater than 6 . in an earlier study, the population proportion was estimated to be 0.33 . how large a sample would be required in order to estimate the fraction of people who black out at 6 or more gs at the 85% confidence level with an error of at most 0.04 ? round your answer up to the next integer.
Answers
Since we need to round up to the next integer, the required sample size for this experiment is 284 people for the confidence level.
To find the required sample size for NASA's experiment, we can use the following formula for the sample size estimation in a proportion experiment:
\(n = (Z^2 * p * (1-p)) / E^2\)
where:
- n is the sample size
- Z is the z-score corresponding to the desired confidence level (85% in this case)
- p is the estimated population proportion (0.33)
- E is the margin of error (0.04)
First, we need to find the z-score for an 85% confidence level. We can look this up in a z-table, or use an online calculator. The z-score for an 85% confidence level is approximately 1.44.
Next, we can plug the values into the formula:
\(n = (1.44^2 * 0.33 * (1-0.33)) / 0.04^2\)
n ≈ (2.0736 * 0.33 * 0.67) / 0.0016
n ≈ 283.66
Since we need to round up to the next integer, the required sample size for this experiment is 284 people.
Learn more about confidence level here:
https://brainly.com/question/22851322
#SPJ11
what is 2/8 plus 7/8
Answers
Answer:
1 1/8
Step-by-step explanation:
2/8 + 7/8
Since the denominators are the same, we add the numerators
9/8
This is an improper fraction, so we can rewrite this
8/8+ 1/8
1 1/8
QUICKEST ANSWER GETS BRAINLEIST.

Answers
The points (80,20) and (120,30) form a proportional relationship. What is the slope of the line that passes through these points
A. 1/4
B. 4
C. 10
D. 40
Answers
Answer:
\(\frac{1}{4}\)
Step-by-step explanation:
Slope = \(\frac{y_2-y_1}{x_2-x_1}\) where the given points are \((x_1,y_1)\) and \((x_2,y_2)\)
Plug the given points (80,20) and (120,30) into the equation
\(\frac{y_2-y_1}{x_2-x_1}\\= \frac{30-20}{120-80}\\= \frac{10}{40}\\= \frac{1}{4}\)
Therefore, the slope of the line that passes through these points is \(\frac{1}{4}\).
I hope this helps!
select all answers that are true.
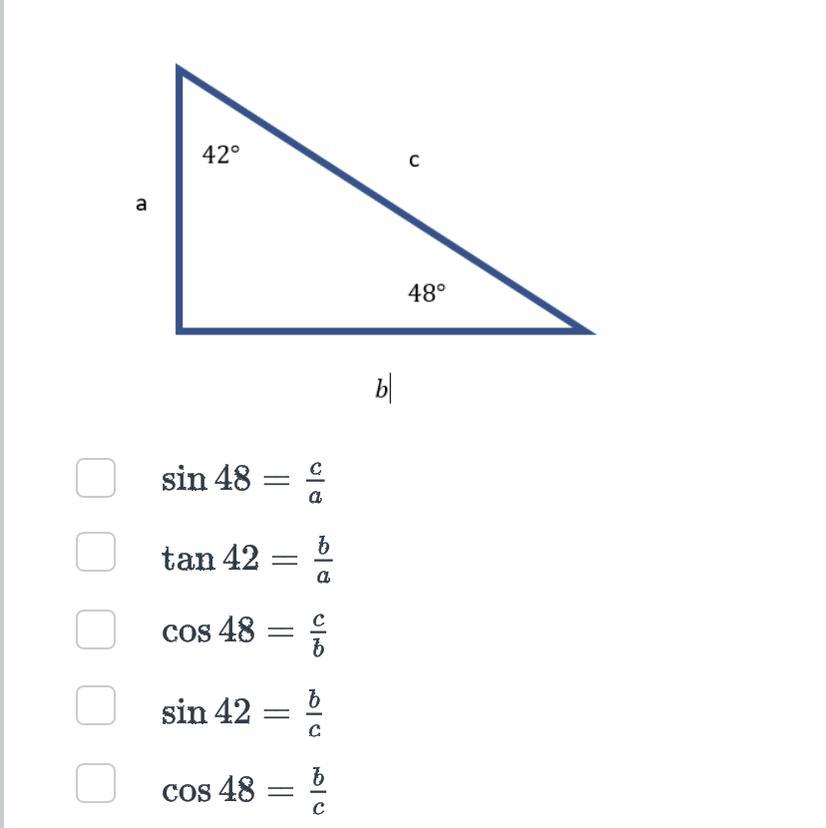
Answers
The correct trigonometry expression are
sin 48 = a/c
tan 42 b/a
sin 42 = b/c
cos 48 = b/c
How to determine the correct expressionsThe correct expression is worked using SOH CAH TOA
Sin = opposite / hypotenuse - SOH
Cos = adjacent / hypotenuse - CAH
Tan = opposite / adjacent - TOA
The right angle triangle is labelled as follows
for angle 48
opposite = a
adjacent = b
hypotenuse = c
for angle 42
opposite = b
adjacent = a
hypotenuse = c
This help us to get the expressions as required
Learn more about Trigonometry here:
https://brainly.com/question/29402966
#SPJ1
Radioactive decay tends to follow an exponential distribution; the half-life of an isotope is the time by which there is a 50% probability that decay has occurred. Cobalt-60 has a half-life of 5.27 years. (a) What is the mean time to decay? (b) What is the standard deviation of the decay time? (c) What is the 99th percentile? (d) You are conducting an experiment which first involves obtaining a single cobalt-60 atom, then observing it over time until it decays. You then obtain a second cobalt-60 atom, and observe it until it decays; and then repeat this a third time. What is the mean and standard deviation of the total time the experiment will last?
Answers
The half-life of an isotope is the time by which there is a 50% probability that decay has occurred if Cobalt-60 has a half-life of 5.27 years then mean time to decay is 7.65 years , standard deviation of the decay time is 3.82 years , the 99th percentile is 36.4 years and the mean and standard deviation of the total time the experiment will last is 6.61 years.
(a) The mean time to decay can be found using the formula: \(mean = half-life / ln(2)\).
Therefore, for cobalt-60 with a half-life of 5.27 years, the mean time to decay is:
\(mean = 5.27 / ln(2) \approx7.65 years\)
(b) The standard deviation of the decay time can be found using the formula:
standard deviation = \(half-life /(\ sqrt{(ln(2))}).\)
Therefore, for cobalt-60 with a half-life of 5.27 years, the standard deviation of the decay time is:
standard deviation = \(5.27 / (\sqrt{(ln(2))}) \approx 3.82 years\)
(c) The 99th percentile can be found using the cumulative distribution function (CDF) of the exponential distribution. For cobalt-60 with a half-life of 5.27 years, the CDF is:
\(CDF(t) = 1 - e^{(-t/5.27)}\)
Setting the CDF equal to 0.99 and solving for t, we get:
\(0.99 = 1 - e^{(-t/5.27)}\)
\(e^{(-t/5.27)} = 0.01\)
\(-t/5.27 = ln(0.01)\)
\(t = -5.27 * ln(0.01)\)
\(t\approx 36.4 years\)
Therefore, the 99th percentile of the decay time for cobalt-60 is approximately 36.4 years.
(d) Three cobalt-60 atoms, then the total time the experiment will last is the sum of the decay times of each atom. Since the decay times are independent and identically distributed, the mean and standard deviation of the total time can be calculated by adding the means and variances of each individual decay time.
The mean of the total time is:
\(mean(total) = mean(atom1) + mean(atom2) + mean(atom3)\)
\(mean(total) = 7.65 + 7.65 + 7.65\)
\(mean(total) = 22.95 years\)
The variance of the total time is:
\(variance(total) = variance(atom1) + variance(atom2) + variance(atom3)\)
\(variance(total) = (3.82)^2 + (3.82)^2+ (3.82)^2\)
\(variance(total) \approx43.67 years\)
The standard deviation of the total time is the square root of the variance:
standard deviation(total) \(= \sqrt{(variance(total))}\)
\(standard deviation(total) \approx6.61 years\)
Therefore, the mean and standard deviation of the total time for observing three cobalt-60 atoms until they decay are approximately 22.95 years and 6.61 years, respectively.
To practice more questions about standard deviation:
https://brainly.com/question/12402189
#SPJ11